Credit : Firman MI
Some of you may have experienced when processing query data on a large database, and you felt that the process was slow and less than optimal. That can happen if the database you are using is not optimized. And for optimization you can use one of the methods by implementing indexing on your database.
So, what is database indexing ?
Same as the index term in books, with indexing we can easily find a topic we are looking for. The purpose of indexing in the database, among others, is to speed up data search based on certain columns.
Index is an object in the database system that can speed up the process of searching or querying data
When the database is created without using an index, the performance of the database server can decrease drastically. This is because CPU resources are widely used for searching data using the table-scan method. Basically a database without indexing will check row by row when running the process, and this will take considerable effort and time if applied to a lot of data.
For example look the visualization table-scan method below:

table-scan method visualization
Now let’s compare it to a table user that has been given an index name with names sorted alphabetically. If the table is sorted alphabetically, the name search can be speeded up because we can check for checking on a particular row. If we find the name ‘Zen’ and we know that the data is in alphabetical order we can just jump down to see if Zen is before or after that row.

Once sorted alphabetically, it takes 3 comparisons to get a matching value instead of 6 times in unindexed data. With index we can create sorted lists without having to create all new sorted table, which would take up a lot of storage space.
So, how index works ?
Indexing is typically used for things like contact lists where data can be physically stored in the order you add contact information, but people will find it easier to find contacts listed in alphabetical order.
Now lets see example below how indexing maps the table.

Here we can see that the table has data stored which is sorted by id which is incremented by the order in which the data was added. And index has names stored in alphabetical order.
Talk about indexing, now we will talk about indexing types. In general, there are two types of indexing databases:
- Clustered
- Non-Clustered
Both clustered and non-clustered indexes are stored and searched using B-Trees, a data structure similar to a binary tree.
B-Tree is a self-balancing tree structure that maintains sorted data and allows, search, sequential access, insertion and deletion in logarithmic time.
Basically it creates a tree-like structure that sorts the data for faster lookups.
Let’s look how b-tree works in our example.

The following is a B-tree of the index we have created. The leftmost path indicates the smallest entry and the rightmost path indicates the largest entry. All queries running will start from the top node and work downwards, if the target entry is smaller than the current node it will take the left path, otherwise it will take the right path. In this case the search starts with Joe, then Nick and ends at Zen.
Some of you may be aware of why the name in the B-tree is truncated. It was an attempt to increase efficiency where the B-tree would limit the number of characters that could be entered into an entry. The B-tree will do it on its own and doesn’t require column data to be delimited. In the example above the B-tree limits entries to 4 characters.
Now lets talk about Clustered Index.
A clustered index is a unique index per table that uses a primary key to organize the data in the table. Clustered index ensures that primary keys are stored in increasing order, which is also the order in which tables are stored in memory. Clustered index has characteristics such as:
- Created when the table is created.
- Use the primary key sorted in ascending order.
You can create clustered index (automatically) like this
create table users (id INT PRIMARY KEY, name VARCHAR)
Once filled, the table will look like this:
users table
The “Users” table already created will have a clustered index automatically, set in the “id” column called “users_pkey”:
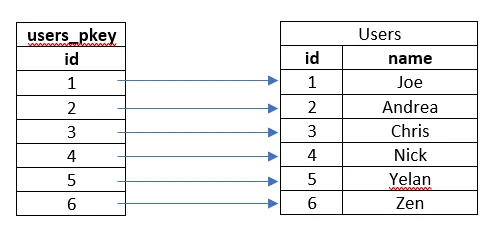
users_pkey clustered index
When we search for data in a table by “id”, the ascending order of the columns allows for optimal search. because the numbers are sorted the lookup can navigate a B-tree which allows the lookup to occur in logarithmic time.
However, to find “name” in the table, we must look at each entry because this column has no index. This is where non-clustered indexes come in handy.
Now lets talk about Non-Clustered Index.
The non-clustered index is sorted for a specific field, from the primary table holding a pointer back to the original table entry. The first example shown is an example of a non-clustered table:

They are used to increase query speed on tables by making columns easier to search. Sorry for the extra column, I don’t know how to remove it from my app drawer :(.
We can create multiple non-clustered indexes. in 2008, we can create up to 999 non-clustered indexes on SQL server and there is no limit on PostgreSQL.
Now you may be curious about when to use index and when not to use it. Ok let’s talk about it.
When to use Indexes
Indexing is meant to speed up database performance, so using indexing every time significantly improves your database performance. As your database gets bigger and bigger, the more likely you are to see the benefits of indexing.
If you are still confused, here I give some points when to use indexing::
- add frequently used columns in where clause or in join condition.
- column containing with a wide range such as flagging
is_deleted, statusetc. - column containing many null values.
- large tables and most queries display data less than 2–4% of the total data.
When not to use Indexes
When data is written to the database, the original table (clustered index) is updated first and then all indexes of that table are updated. each time a write is made to the database, the index cannot be used until it is updated. if the database keeps receiving writes then the index will never be usable.
Here I give some points where we don’t need to use indexing:
- Small table.
- Columns that are not often used as conditions in queries.
- Most queries return more than 2–4% of the total data.
- Frequently updated tables.
NOTE: The newest version of Postgres (that is currently in beta) will allow you to query the database while the indexes are being updated
Finally, Last but not least. Let’s test indexing performance!!
Here I will test indexing performance using PostgreSQL. To test if indexing will reduce query time, you can run a set of queries in your database, record the time it takes for those queries to complete, then start creating indexes and rerun your tests.
Here I have a database with a total data of 100k. I use a count estimate query so that the data calculation is faster.

estimate count row data
To do this, try using the EXPLAIN ANALYZE clause in PostgreSQL:
EXPLAIN ANALYZE SELECT * FROM users WHERE name = 'Andrea';Where will this produce:

The results above show that the query takes 22,798 ms to find the data named “Andrea”.
Now let’s create an index to “name” column and run explain and analyze query again with this line:
CREATE INDEX users_name_idx ON public.users ("name");
EXPLAIN ANALYZE SELECT * FROM users WHERE name = 'Andrea';
And now our database will produce like this:
table with indexed result
We can see that after we add an index to the “name” column, the time needed to search the query is reduced significantly, from the beginning it took 22.798ms and after adding the index to 0.299ms, which means cutting 22 milliseconds of processing time.
Index Types:
- B-Tree is the default indexing type that can be obtained when querying
create index. almost all databases will have B-tree indexing. The B-tree tries to stay balanced, with approximately the same amount of data in each branch of the tree. Indexing can operate against all data types, and can also be used to retrieve NULL values. B-trees are designed to work very well with caching, even when only partially cached. - Hash Indexes pre-Postgres 10 are only useful for equality comparisons, but you pretty much never want to use them since they are not transaction safe, need to be manually rebuilt after crashes, and are not replicated to followers, so the advantage over using a B-Tree is rather small. In Postgres 10 and above, hash indexes are now write-ahead logged and replicated to followers.
- Generalized Inverted Indexes (GIN) are useful when an index must map many values to one row, whereas B-Tree indexes are optimized for when a row has a single key value. GINs are good for indexing array values as well as for implementing full-text search such as jsonb data type.
- Generalized Search Tree (GiST) indexes allow you to build general balanced tree structures and can be used for operations beyond equality and range comparisons. They are used to index the geometric data types, as well as full-text search such as jsonb data type.
Conclusion time!!
So, after all this discussion what makes indexing so effective? ?
Indexing does not change the existing document/table that is being applied, but rather creates a new data structure that has two blocks for each entry. the two blocks are:
- The data field where the index is created.
- Pointer to the row/document where the data field is stored in the database.
and how does search improve after implementing indexing ?
- Now instead of linearly searching through all the fields inside the database, searching is made in a Binary search fashion. [Which reduces the searches from N to (Log N)].
Hence, saving our compute. - The sequential flow through the connected blocks in memory is also reduced to only 2, as after indexing there are only two fields in the new data structure created.
Well, we are at the end of the discussion, hopefully what is described here is useful. Actually I want to discuss indexing using hash-index, GIN and GIST at the same time, but I think I will discuss it in the next session. Thanks for reading, happy coding!! :D